Created: 2022-03-16 22:20
Resources
2023-03-28
Here’s an example of an application that supports asking questions about a long PDF file.
There are 3 relevant parts:
- The static processing of the PDF file, by splitting it into smaller chunks and storing them in a Vector Store.
- The matching of the question with the potentially relevant chunks. Rather than sending all the data of the PDF as context to the model (GPT4 in this case), only the parts that have content similar to the question are sent.
- Sending the question and to context to the model to get an answer.
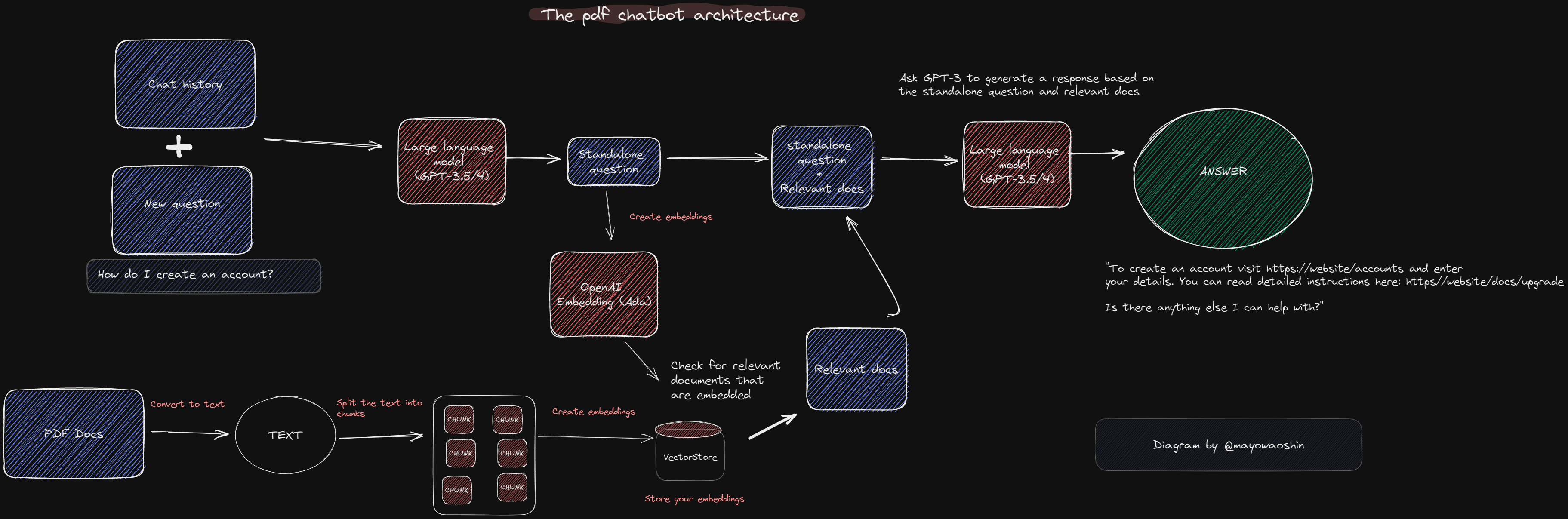
Reference: gpt4-pdf-chatbot-langchain by @mayowaoshin.
Fine tune vs. context with Vector Store
Fine tune an LLM model is the process of further training the model on some data. Since the indexed data (TS files) is constantly changing as new versions of the code are published, it seems like fine tuning is not what I want as the way to build the “index”.
Besides, the training data set is not necessarily used as the search space of the LLM:
Although the LLM will learn patterns and associations from the data, it does not “memorize” the entire dataset. Instead, it generalizes from the data to generate responses based on the patterns it has observed during training.
But it could be used improve the model’s ability to search TS code by type signature. Which I assume could be done by hand picking a certain amount of files and some queries and feeding that into the LLM for fine tuning.
Providing context with a Vector Store at first seems like the way to go. The problem is this is limited to the amount of context the LLM can take. Eg. GPT4 can take 32k tokens, which is way shorter than all the TS code Tsearch should index from NPM.
These are the current stats of DefinitelyTyped, which only includes the packages that do not publish their own types.
| Language | Files | Lines | Code | Comments | Blanks |
|---|---|---|---|---|---|
| TSX | 880 | 124789 | 104730 | 6939 | 13120 |
| TypeScript | 38772 | 6744072 | 2713518 | 3487433 | 543121 |
And even if it were possible to provide all the code of the search space as context, it would still mean processing all that context on each query.
2023-03-24
Did a quick experiment where I gave ChatGPT (v4) a list of TS files with exported functions and asked it to query the files using the Tsearch query format. Overall it gave me some accurate results.
It did mess up a few times in the output what the signature of the function in the result was, but it was easy to correct it.
It understood functions with arguments in different order and/or curried.
It also gave the correct results when using different names for the generics in a query.
For example, these two queries produced the same result:
(A => B), A[] => B[](T => U), T[] => U[]
[
{
"module": "fp-utils",
"file": "Array.ts",
"location": 1,
"signature": "<A, B>(f: (a: A) => B) => (as: A[]) => B[]",
"name": "map"
},
{
"module": "some-module",
"file": "array.ts",
"location": 1,
"signature": "<A, B>(as: A[]) => (f: (a: A) => B) => B[]",
"name": "convert"
}
]This makes we rethink the approach on Tsearch, maybe I could use something like LangChain to fine tune an LLM and use that to power Tsearch, instead of building a search index and algorithm by hand.
Open questions
Solving the problem of getting results that aren’t relevant (false positives?) seems relatively easy but asking to show results that it didn’t include (false negatives?) seems harder to solve. The intuition I have her is that I would have to build Tsearch by hand (ie. index and search algorithm) to get the correct results and use that to fine tune (or train?) the model. Which defeats the purpose of using an LLM powered solution rather than building one by hand.
Resources
2023-02-09
Copied some old notes, circa 2020 Tsearch, old notes
2023-02-05
Given a function like this one:
import * as O from 'fp-ts/Option'
export const get1 = (n: number): O.Option<number> =>
n === 1 ? O.some(1) : O.noneThe return type is Option<number>, which is an union type (Some<A> | None) but in this case it probably makes more sense do nominal matching, since a query to find such function won’t use the union type form.
Side note: could a LLM be used to implement the search, instead of a “traditional” solution of building an index and a search algorithm?
2023-02-05
Back to it, hoping to go slow but steady and consistent this time 🤞
Played a bit with ts-morph. It’s relatively simple to get the basic types parsed out, I should define a set of what are the most searchable ones and making something that works with those (eg. nobody will search for a complex struct type, right?).
Nominal search is still useful. That means storing types by name as well. And matching structure against names. Eg. given the following code:
type Foo = string
export const f = (foo: Foo): number =>
foo.lengthIf the user searches for both string => number and Foo => number, the function should show up in the results.
This gets more complex for non primitive types. Eg. what about a config type?
// Library A
type Config = { /* ... */ }
const makeY = (config?: Config): Y => { /* ... */ }
// Library B
interface Config { /* ... */ }
const instantiateX = (config?: Config): X => { /* ... */ }These two Config types are different, but they would show up in a query such as Config => _. Which is probably what the user wants.
Then the application could help the user to narrow down the results for to only search for one libraries Configs.
2022-06-16
First prototype of the trie based search.
Next steps
How to model the following with the trie?
- Functions that take no arguments
- Curried vs. uncurried functions
- Generics
- Functions as arguments (or return types?)
What’s the proper representation of a query?
data Query = Query
{ args :: [Type]
, ret :: Type
}
data Query_
= Fn Type Query_
| Ret TypeSpecial cases
Well known types, specially function types, could be treated as specially cases. Since, well, they are well known. Some examples:
() => void- The identity function
- Specialized versions of the identity function
- Callbacks:
(data?: T, error?: Error) => void
Async and effectful code
Should a search for a => b return a => Promise<b>?
And should a => Promise<b> return a => b?
Heuristics to detect effectful code, both sync and async can help in returning useful approximate results.
For example, detecting callbacks and treating them as special cases. Or returning callback based code (and vice versa) when searching for function la re returning Promise
2022-05-17
Thinking more about the trie approach I realize that generics and higher order functions do not fit well into that representation.
type f =
(cb: (data?: unknown, error?: Error) => void) =>
void;
type g =
(s: string) =>
(r: RegExp) =>
string
type h =
<A, B>(f: (a: A) => B) =>
(as: A[]) =>
B[]
type i =
<A>(f: (a: A) => B) =>
(as: A[]) =>
B[]
type flap =
<A>(a: A) =>
<B>(fab: Option<(a: A) => B>) =>
Option<B>2022-05-13
Search algorithm
Partial matches
Partial matches of the same amount of arguments are easy to find, just just a traversal of the tree.
Does it even make sense to show results of functions with different number of arguments? If no, what about optional arguments?
Argument ordering
- How to deal with permutations in the ordering of arguments?
- Do we want all the permutations or just some heuristics of the permutations that would make sense (eg. swap first with last)?
- Do we want to be stricter on the matching of permutations vs. approximate types (eg.
stringmatches withstring | numberonly if in the right position)? - How to take into account curried functions in the current tree?
Variance and covariance
What role do these play in the search algorithm? Do we want both variant and covariant results? Or only one type? Could the user control that?
Metadata and conventions
Since TypeScript type signatures also include the names of the arguments, could that be used in the matching?
Eg. config or options could be handled in some special way when present as the last and optional argument,.
Code structure
Is there some benefit to splitting the projects further and have the executable (artifacts?) be separate projects? Is this too granular? Would this affect publishing?
cabal.project
api-lib/
|__ tsearc-api-lib.cabal
server/
|__ bin/
| |__ Main.sh
|__ server.cabal
cli/
|__ bin/
| |__ Main.sh
|__ cli.cabal
tsearch/
|__ src/
| |__ Tsearch.sh
|__ tsearch.cabal
Stack vs. Cabal
What about using Stack again? Maybe it’d work nicer with Nix, based on Syd’s pattern
2022-05-12
IDE support
A VSCode extension would probably drive a lot of adoption. There’s one for Elm already to steal code from => vscode-elm-signature
Hoogle however is mainly used in the browser and as the CLI interface (my guess).
What would the benefits of having the search in the editor?
- Avoid context switching
- Integration with IDE features like providing some sort of LSP or using the TS LSP to keep the index up to date.
- Go to defintion on the results
- Indexing the current project
Search algorithm
Draw a visual representation of the TsTrie on stream today.
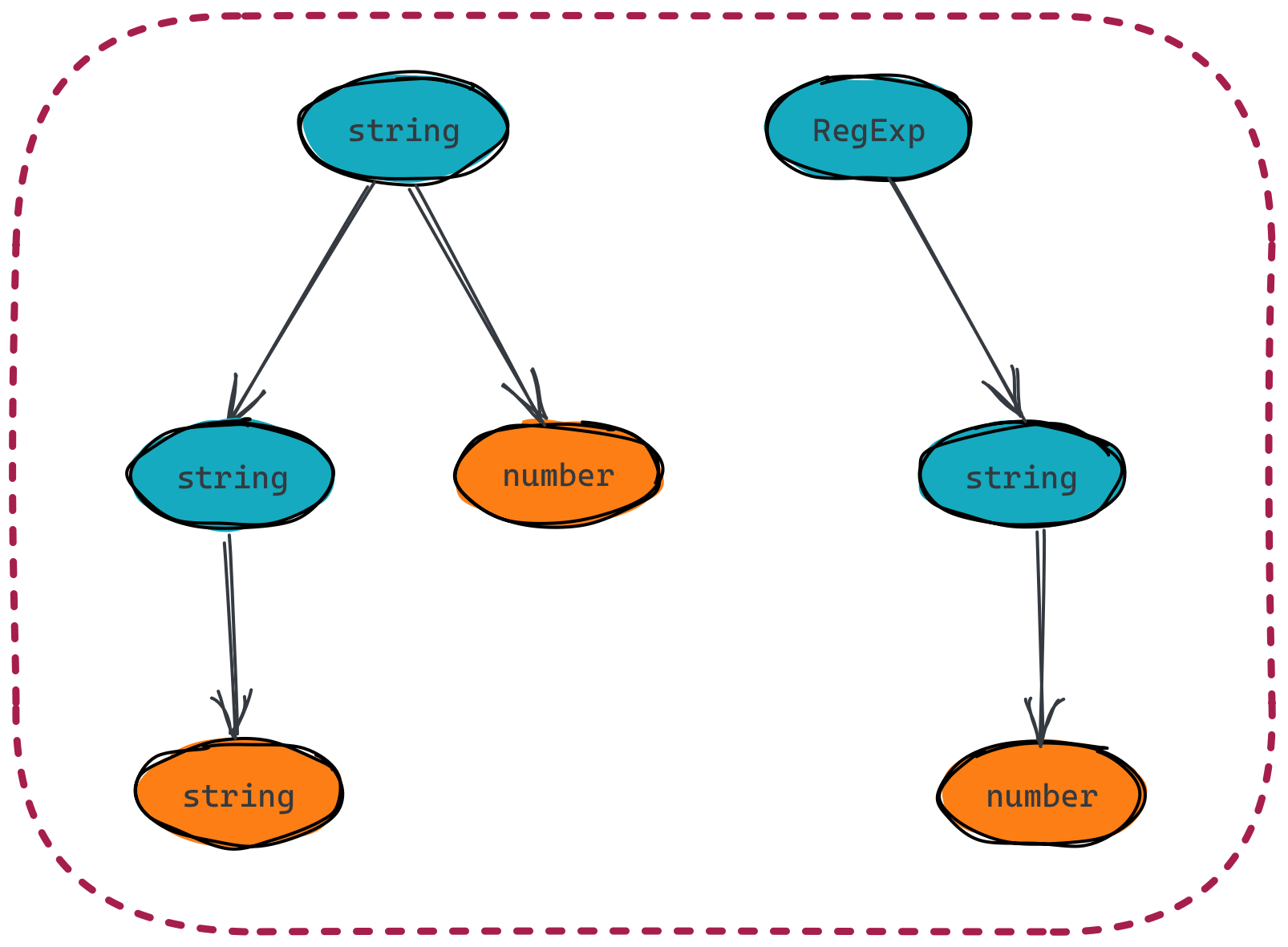
While this data structure is good for finding exact matches I’m not sure how easy/hard it’d be to look for partial matches.
2022-05-05
Worked on stream to remove Servant from the server to simplify things. But got stuck with Nix so Chiroptical will help me. Should be done next week.
Also started the frontend from scratch as well with the NextJS starter and Tailwind.
Code structure
apps/
|__ cli/Main.sh
|__ server/Main.sh
src/
|__ Tsearch.hs
src/Tsearch should only contain code to perform searches. It should not have the code for the metrics, server, or CLI. In other words, we don’t want to depend on stuff like wai on the CLI.
2022-04-29
Finally started to work on the project again, during the stream. For now I got the client and server up and running again.
I should do more Thinking exercises to define what to work on next:
- Search algorithm, based on 2022-03-24 idea.
- Rewrite the extractor and add some of the due improvements.
- Website from scratch with Next,
fp-ts, Tailwind.
The key would be do some actual work that would advance the project and not get sidetracked by what would look like important but isn’t (like the client rewrite).
2022-03-29
Thanks to the chat with Riccardo (Riccardo Odone) I realized Tsearch can be my niche for streaming. Which is a two birds with one stone type of situation.
It is a very specific problem I’d be trying to solve, and switching from a guy that streams random FP stuff to the guy that works on Tsearch on stream changes the whole perspective of the stream. Having a set topic also reduces the cognitive load by a lot as I don’t have to think about what am I going to stream or feel the preasure on the topic being interesting to people.
And a nice side effect, streaming the process can be a nice way to develop accountability on working with Tsearch untill I have something usable.
2022-03-24
I did a few Thinking exercises during the last few days.
For the type search I think a trie like data structure that models the arguments of a function as nodes and its return type as leaves could work really nicely.
data Arg =
Arg
TsType
[Arg] -- Next argument
[Return] -- Return type
data Return =
Return
TsType
[ID] -- Ref to the function => Map ID Fn
data TsTrie = TsTrie [Arg]It is really great to model simple functions like these ones:
const A: (a: string, b: string) => number
const B: (a: RegExp, b: string) => boolean
const C: (a: string) => numberHowever I do have a couple of open questions
- How to handle higher order functions?
- What would be the space requirements for such tree? Could it explode in size and not make sense to have it all in memory? Does Haskell laziness help here?
- What other information I have to save about types that can be useful to search?
- How many times the type shows up in that position
- What’s the argument name, ie. to make the match stronger if the name is the same
- How many other (similar) occurrences of the function are. More specific should show first?
- What other information do I have to store in the nodes, leaves, and vertices?
2022-03-16
How can I get the project started again? Should I do a series of Thinking exercises to figure out the next steps?
Slow iterations with a clear goal and milestones can be something to try out.
Defining milestones
Before setting any milestones, the goals, the big picture (as in systems design) and, more importantly, the principles have to be clearly defined.
Goals
Hoogle for TypeScript.1
Principles
- Pragmatic working solutions over large feature set. Better to support very well a subset of TS that have bad support for the whole language space. Leaving out React is fine at the start.
- Make ir work for a group then generalize. Similar to the previous point, limit how much of the ecoystem is covered or I attempt to cover. Rather support the fp-ts community first and slowly grow from there than attempt to make a solution that works for everyone from the start.
- Useful. Solve real every day productivity problems. Make the experience of working with TypeScript better.
- Works with your tooling. Meet people were they are. Support integrations with VS Code and he popular tools people use.
- Local first. Focus on working locally for the current project.
- Tools over contributions. Pick the tools that make it easier to build the project in the best way rather than some super accessibility but sub par tool (ie. Haskell/Rust instead of JS/TS).
- Show don’t tell. In the past announcing things and making a big noise out of it didn’t work. Let’s not repeat history. A working solutions are the only thing I will talk about publicly, unless requesting help with a hard problem.
- Read, think, plan, then implement. There’s some literature on the topic, make sure to consume that first before working on something that I’ll have to end up changing layer.
Footnotes
-
Although Hoogle is a hell of an inspiration, I don’t want it tool limit what Tsearch can be. It should have a better looking UI, for example. ↩